 redis 数据类型对应的数据结构
redis 数据类型对应的数据结构
# 压缩列表 (ziplist) 介绍
redis 为了节约内存,设计了压缩列表的数据结构,由一系列特殊编码的内存块构成的列表, 一个 ziplist 可以包含多个节点(entry), 每个节点可以保存一个长度受限的字符数组。每个元素都保存的数据长度信息,这样就可以按长度读取数据,而不需要提前分配好固定大小的数据。
可以与数组对比,数组中的每个元素大小都是相同的,实际使用中,我们存的数据有大有小。
ziplist 节点构成
area |<------------------- entry -------------------->|
+------------------+----------+--------+---------+
component | pre_entry_length | encoding | length | content |
+------------------+----------+--------+---------+
1
2
3
4
5
2
3
4
5
- pre_entry_length 记录了前一个节点的长度,通过这个值,可以进行指针计算,从而跳转到上一个节点
- encoding 和 length 两部分一起决定了 content 部分所保存的数据的类型(以及长度)
- content 部分保存着节点的内容,类型和长度由 encoding 和 length 决定。
ziplist 的完整实现要复杂许多,更多信息可以查看:https://redisbook.readthedocs.io/en/latest/compress-datastruct/ziplist.html#ziplist (opens new window)
# 字符串 - string
在 Redis 中, 只有能表示为 long 类型的值, 才会以整数(long)的形式保存, 其他类型的整数、小数和字符串, 都是用简单动态字符串(sdshdr) 结构来保存
s
 (图片来源网络)
(图片来源网络)
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used 已使用长度 */
uint8_t alloc; /* excluding the header and null terminator 实际分配的长度,一般大于 len */
unsigned char flags; /* 3 lsb of type, 5 unused bits 头部类型 */
char buf[]; /* 实际保存的数据 */
};
1
2
3
4
5
6
2
3
4
5
6
# 列表 - list
有 2 中实现
- 双向链表
- 压缩列表:需要同时满足以下两个条件
- 列表中保存的单个数据小于 64 字节
- 列表中数据个数少于 512 个
# 字典 - hash
有 2 中实现
- 散列表(MurmurHash2 (opens new window))
- 使用 链表解决哈希冲突问题
- 随着元素个数增、减会动态扩容、缩容
- 压缩列表:需要同时满足以下两个条件
- 字典中保存的键和值的大小都要小于 64 字节
- 字典中键值对的个数要小于 512 个
# 集合 - set
有 2 中实现
- 整数数组
- 散列表:需要同时满足以下两个条件
- 存储的数据都是整数
- 存储的数据元素个数不超过 512 个
# 有序集合 - sortedset
有 2 中实现
- 跳表 (opens new window)
- 压缩列表:需要同时满足以下两个条件
- 所有数据的大小都要小于 64 字节
- 元素个数要小于 128 个
# 汇总
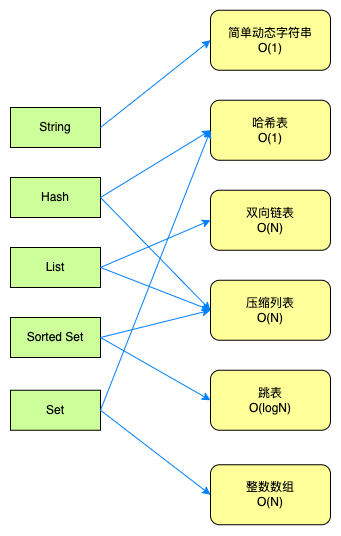
| 数据结构 | 查询时间复杂度 |
|---|---|
| 哈希表 | O(1) |
| 跳表 | O(log N) |
| 双向链表 | O(N) |
| 压缩列表 | O(N) |
| 整数数组 | O(N) |
另外,即使是同一种数据类型的,不同操作的时间复杂度也会不同,具体可以查看 redis 官方文档。
以 HMGET 为例:时间复杂度是 O(N)
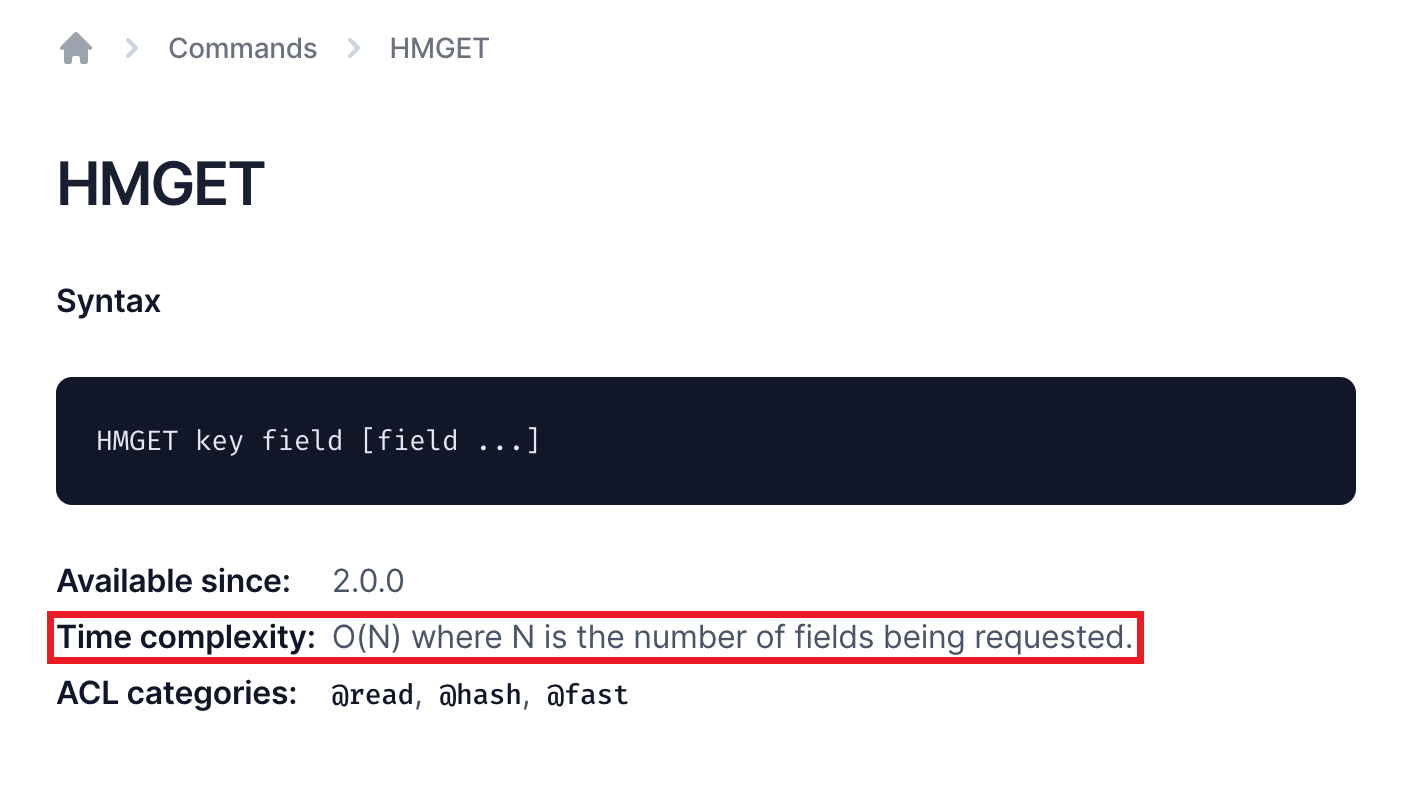
https://redis.io/commands/hmget/ (opens new window)
# 参考
Last Updated: 2024/05/12, 15:25:49