 redis 数据持久化
redis 数据持久化
redis 作为缓存服务,同样也提供了持久化配置选项,支持4种持久化模式:AOF、RDB、NO persistence(不持久化)、RDB + AOF(组合模式,4.0+版本支持)
官方文档:https://redis.io/docs/management/persistence/ (opens new window)
# AOF(append only file)
AOF 模式在数据写入内存后再写一条命令到 AOF 文件中,类似 MySQL 的 redo log。
例如执行一个 set 操作
127.0.0.1:6379> set hello world
OK
2
对应的日志
*2
$6
SELECT
$1
0
*3
$3
set
$5
hello
$5
world
2
3
4
5
6
7
8
9
10
11
12
稍微解释一下含义
*2表示命令氛围2部分$6表示接下来的部分包含6个字符,即:SELECT$1表示接下来部分包含1个字符,即:0
组合起来就得到SELECT 0,即选择db 0数据库。
*3表示命令包含3部分$3表示接下来的部分包含3个字符,即:set$5表示接下来的部分包含5个字符,即:hello$5表示接下来的部分包含5个字符,即:world
组合起来就得到set hello world。
当 redis 重启时,就会根据 AOF 日志重放历史命令,生成对应数据。
如果每次写操作都要写 AOF 日志(磁盘IO),对 redis 性能影响比较大,所以 redis 提供了3种写回策略,对应参数是appendfsync。
| appendfsync | 优点 | 缺点 | 说明 |
|---|---|---|---|
| always | 数据基本不丢失 | 每次都要磁盘IO,性能差 | 同步写回,每个写操作都落盘,通常不建议使用 |
| everysec | 性能适中 | 宕机可能丢失1秒数据 | 每秒写回 |
| no | 高性能 | 宕机丢失较多数据,不可控 | 日志写入缓冲区,由操作系统控制写回 |
因为 AOF 是记录执行的命令,如果运行时间比较长,aof 日志文件会比较大,同样会在数据恢复时也需要较长时间。为了解决这个问题,引入了 aof 重写机制。
# AOF 重写(aofrewrite)
AOF 重写,是将多个命令合并成一个命令,例如:
set a hello
set a world
2
a最终的值是world,那么只需要记录set a world就可以了,这样就能压缩 aof 文件大小,在数据恢复时需要执行的命令也会减少,可一定程度提高数据恢复速度。
触发时机:
- 执行
bgrewriteaof命令 - 到达配置阈值
# 自动触发 aofrewrite 的文件大小
auto-aof-rewrite-min-size 128mb
# 自动触发 aofrewrite 的增长率
# 例如配置是100,当文件大小到达 128mb 时,触发第一次 aofrewrite
# 当文件大小到达 265mb 时(前一次大小的 100%),触发第二次 aofrewrite
auto-aof-rewrite-percentage 100
2
3
4
5
6
aof 重写会从主进程 fork 一个子进程来完成,整个过程不会阻塞主线程,在重写没有完成期间的命令,会写入aof 重写缓冲区。
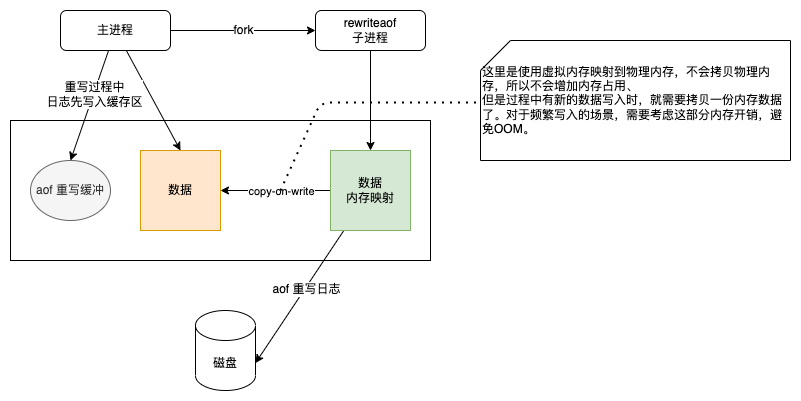
完整配置参考
# 开启 aof 日志
appendonly yes
# appendfsync always
# appendfsync no
appendfsync everysec
# aof 日志文件路径
appendfilename "appendonly.aof"
# 自动触发 aofrewrite 的文件大小
auto-aof-rewrite-min-size 128mb
# 自动触发 aofrewrite 的增长率
auto-aof-rewrite-percentage 100
# 当 aof 文件出现错误时,是否忽略错误继续执行
aof-load-truncated yes
2
3
4
5
6
7
8
9
10
11
12
13
# RDB
RDB 保存的是某一时刻的全量内存快照,记录的是数据(二进制),AOF 记录的是操作。在服务重启恢复数据的时候比 AOF 速度更快。
但因为是生成全量快照,所以会比 AOF 追加的方式需要更多时间来生成备份。
触发生成 RDB 机制
执行
save命令,谨慎使用,会阻塞主线程,在一些特殊场景可以使用(例如停机升级)执行
bgsave命令,和 AOF 一样,紫金城 fork 主进程来完成快照生成,不会阻塞主线程对外服务,同样也是 copy-on-write 机制,生成 RDB 文件过程中只会对修改的数据增加内存开销配置文件定时生成
# 当条件满足时自动触发 bgsave # save <seconds> <changes> # # 在900秒内发生1次修改 save 900 1 # 在300秒内发生10次修改 save 300 10 # 在60秒内发生10000次修改 save 60 100001
2
3
4
5
6
7
8全量复制(主从同步时)
debug reload
shuedown
# 混合模式
AOF 和 RDB 各有优缺点
| 持久化 | 文件生成效率 | 数据恢复速度 | 文件大小 | 数据丢失情况 |
|---|---|---|---|---|
| AOF | 快 | 慢 | 大,和写操作次数线性增长 | 配置为everysec丢失1秒数据 |
| RDB | 慢 | 快 | 小,和数据量线下增长 | 丢失生成快照期间的数据,由数据量大小决定 |
在 redis 4+版本之后,支持了混合模式。开启混合模式后,执行bgrewriteaof命令,AOF文件头部将会以 RDB 格式存储,在数据备份过程中产生的增量数据,将会以 AOF 方式追加在文件末尾。
nodejs 写了个测试脚本,在开启混合模式的情况下,往 redis 写了1k万个数据。
import { createClient } from "redis";
const redis = createClient({
url: 'redis://localhost:6379'
});
async function main () {
await redis.connect();
for (let i = 0; i < 10000000; i++) {
await redis.set(`key-${i}`, `value-${i}`);
}
await redis.disconnect();
}
await main()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
在Apple M1 Pro 16G内存上测试,执行save操作(阻塞方式生产 RDB 文件),需要6.85s,生成的文件大小是。
| 类型 | 大小 |
|---|---|
| AOF | 304M |
| AOF 重写 | 255M(混合模式文件头就是以 RDB 格式保存,符合理论) |
| RDB | 255M |
配置参考
# 关闭自动 RDB
save ""
# rdb 文件名
dbfilename dump.rdb
dir ./
stop-writes-on-bgsave-error yes
# 文件压缩
rdbcompression yes
# 检查文件合法性
rdbchecksum yes
# 开启 aof
appendonly yes
# aof 文件名
appendfilename "appendonly.aof"
# 每秒刷盘
appendfsync everysec
# 当 aof 文件出现错误时,是否忽略错误继续执行
aof-load-truncated yes
# 开启混合模式
aof-use-rdb-preamble yes
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 常见问题
- 虽然 Redis 是单线程提供服务的,但是还会有很多其他后台线程,例如生成 AOF 和 RDB 文件的线程,删除过期 key 的线程等。
- 虽然生成 AOF 和 RDB 时不会真正拷贝物理内存,但是 copy-on-write 机制在数据写入时为了不影响主线程数据写入,会将内存拷贝一份需要修改的数据
# 案例分析
如果一个双核服务器部署 redis 实例,在数据量比较大的情况下执行bgsave命令会有什么风险?
redis 除了主线程外,还有后台线程,数据量大的情况下执行
bgsave需要占用比较多的时间,主线程占用一个cpu,只剩下一个cpu,就造成资源竞争,影响性能
在一个读写比例大概 8: 2 的 redis 实例中,当前服务器物理内存4G,redis 中有3G数据,执行bgsave或者bgrewriteaof命令会有什么风险?
bgsave或者bgrewriteaof都是 fork 主进程,使用 copy-on-write 机制生成备份文件,在次期间,写操作占0.8,也就是2.4G数据,导致物理内存不足,会使用 swap 分区充当虚拟内存,性能会严重下降。如果没有开启 swap,还会导致 OOM。